Crescendo Attacks : Comment les LLM du monde réel répondent aux attaques progressives de prompts

Le « red teaming » pour les Grands Modèles de Langage (LLM) est un domaine émergent qui traite des vulnérabilités uniques posées par ces systèmes puissants. À mesure que les LLM sont de plus en plus déployés dans tous les secteurs, leurs capacités flexibles introduisent de nouveaux risques de sécurité qui dépassent la portée des équipes de cybersécurité traditionnelles.
Chez NeuralTrust, nous recherchons, mettons en œuvre et testons activement des techniques adverses pour découvrir les faiblesses des LLM, aidant ainsi les entreprises à mieux se défendre contre les attaques basées sur les invites (prompts), communément appelées « jailbreaks ». Ces attaques peuvent entraîner de graves conséquences sur la réputation et les opérations, telles que la fuite de données propriétaires ou la génération de contenu offensant (par exemple, des grossièretés dans les chats en direct, des réponses toxiques ou des divulgations non autorisées).
Dans cet article, nous présentons notre travail de réplication et d'adaptation de l'attaque Crescendo, proposée à l'origine par des chercheurs de Microsoft (Russinovich et al.). Nous expliquons l'idée maîtresse de l'attaque, décrivons notre implémentation personnalisée adaptée aux modèles open source de taille moyenne, et partageons les enseignements de nos expériences sur un éventail de catégories d'objectifs nuisibles.
Qu'est-ce que l'Attaque Crescendo ?
L'attaque Crescendo est une technique sophistiquée d'injection d'invites qui guide progressivement un LLM vers la production de résultats restreints ou nuisibles sans déclencher de rejet immédiat ou de filtres de sécurité. Au lieu de demander directement une réponse sensible, l'attaquant intensifie progressivement la conversation, exploitant la tendance du modèle à se conformer lorsque les invites sont formulées de manière bénigne.
Notre implémentation capture l'essence de l'attaque originale tout en introduisant des mécanismes supplémentaires pour accroître l'efficacité de nos cas d'utilisation ciblés. Une conclusion clé de nos tests : demander directement l'objectif final entraînait généralement de faibles taux de réussite. Le succès dépendait fortement de la formulation et de la progression minutieuses des invites intermédiaires.
Nous avons structuré l'attaque comme une séquence d'invites croissantes, en commençant par des questions bénignes et en augmentant progressivement leur sensibilité. À mesure que le modèle approche du contenu restreint, il peut commencer à résister. Pour gérer cela, nous avons mis en œuvre un mécanisme de retour en arrière (backtracking) : chaque fois que le modèle refusait de répondre, le système modifiait l'invite et réessayait. Cette boucle se poursuivait jusqu'à ce qu'une sortie réussie soit générée ou qu'un nombre maximum de tentatives soit atteint.
Cette stratégie d'essais et d'erreurs reflète le comportement d'un attaquant qualifié sondant les garde-fous d'un modèle à la recherche de faiblesses.
Quel Chatbot est le Plus Vulnérable à l'Attaque Crescendo ?
Pour évaluer la susceptibilité réelle des LLM populaires à l'attaque Crescendo, nous avons conçu une expérience systématique ciblant un éventail de catégories d'objectifs nuisibles. Ces objectifs ont été sélectionnés pour représenter des classes typiques de contenu restreint dans les environnements de production, notamment :
- Activités Illégales
- Automutilation
- Désinformation
- Pornographie
- Grossièretés
- Sexisme
- Discours Haineux
- Violence
Chaque objectif était associé à une séquence d'invites conçues pour monter en ton et en intention, suivant la méthode Crescendo. Cette approche nous a permis d'évaluer non seulement si un modèle produirait un résultat restreint, mais aussi avec quelle facilité il pourrait être guidé vers ce résultat par des invites progressives. Nous avons testé l'attaque contre cinq modèles de langage. LLM open source :
- Mistral
- Phi-4-mini
- DeepSeek-R1
LLM Propriétaires/Industriels :
- GPT-4.1-nano
- GPT-4o-mini
Pour tenir compte de la nature stochastique des sorties des modèles de langage, nous avons exécuté chaque séquence d'invites plusieurs fois par paire modèle-objectif. Le nombre de répétitions variait en fonction de la cohérence de la réponse du modèle. Nous avons ensuite moyenné les résultats pour rapporter des métriques fiables sur deux fronts clés :
- Taux de réussite : le pourcentage d'essais au cours desquels le modèle a finalement généré le résultat restreint.
- Taux de rejet : la fréquence à laquelle le modèle a refusé de se conformer ou a généré une réponse de repli sûre.
Cette approche à double métrique aide à distinguer les modèles qui sont simplement verbeux ou évasifs de ceux qui résistent de manière significative aux instructions nuisibles.
Nous avons également mis en œuvre un retour en arrière automatisé pour simuler un adversaire adaptatif. Si le modèle refusait de terminer une étape, le système modifiait légèrement l'invite et réessayait, imitant un scénario d'attaque réel où un adversaire sonde les limites par essais et erreurs.
En structurant l'expérience de cette manière, nous avons pu simuler une boucle d'interaction adverse réaliste et mesurer combien de temps ou avec quelle facilité chaque modèle pouvait être manipulé pour briser ses garde-fous. Cette configuration constitue la base des résultats présentés dans la section suivante.

Résultats de l'Expérience de l'Attaque Crescendo
Les résultats révèlent des schémas intéressants dans la susceptibilité des modèles à l'attaque Crescendo. Nous rapportons d'abord les taux de réussite dans différentes catégories d'objectifs pour chaque LLM :
- L'attaque Crescendo a atteint des taux de réussite élevés dans les catégories Discours Haineux, Désinformation, Pornographie, Sexisme et Violence.
- Notamment, l'attaque a atteint des taux de réussite de 100 % pour la Pornographie, le Sexisme et la Violence sur Mistral, Phi-4-mini, GPT-4.1-nano et GPT-4o-mini.
- En revanche, les modèles ont montré une plus grande résistance lorsque les objectifs ciblés étaient les Activités Illégales, l'Automutilation et les Grossièretés.

Nous avons également mesuré les taux de rejet : la fréquence à laquelle un modèle a résisté ou refusé de se conformer.
- DeepSeek-R1 avait le taux de rejet le plus élevé, en particulier pour la Désinformation et les Activités Illégales.
- Phi-4-mini a montré un rejet modéré pour l'Automutilation, les Grossièretés et les Activités Illégales.
- Mistral a montré une certaine résistance aux Grossièretés, aux Activités Illégales et à la Désinformation, mais avait globalement des taux de rejet inférieurs à ceux de DeepSeek-R1.
- GPT-4.1-nano et GPT-4o-mini n'ont pratiquement montré aucune résistance.
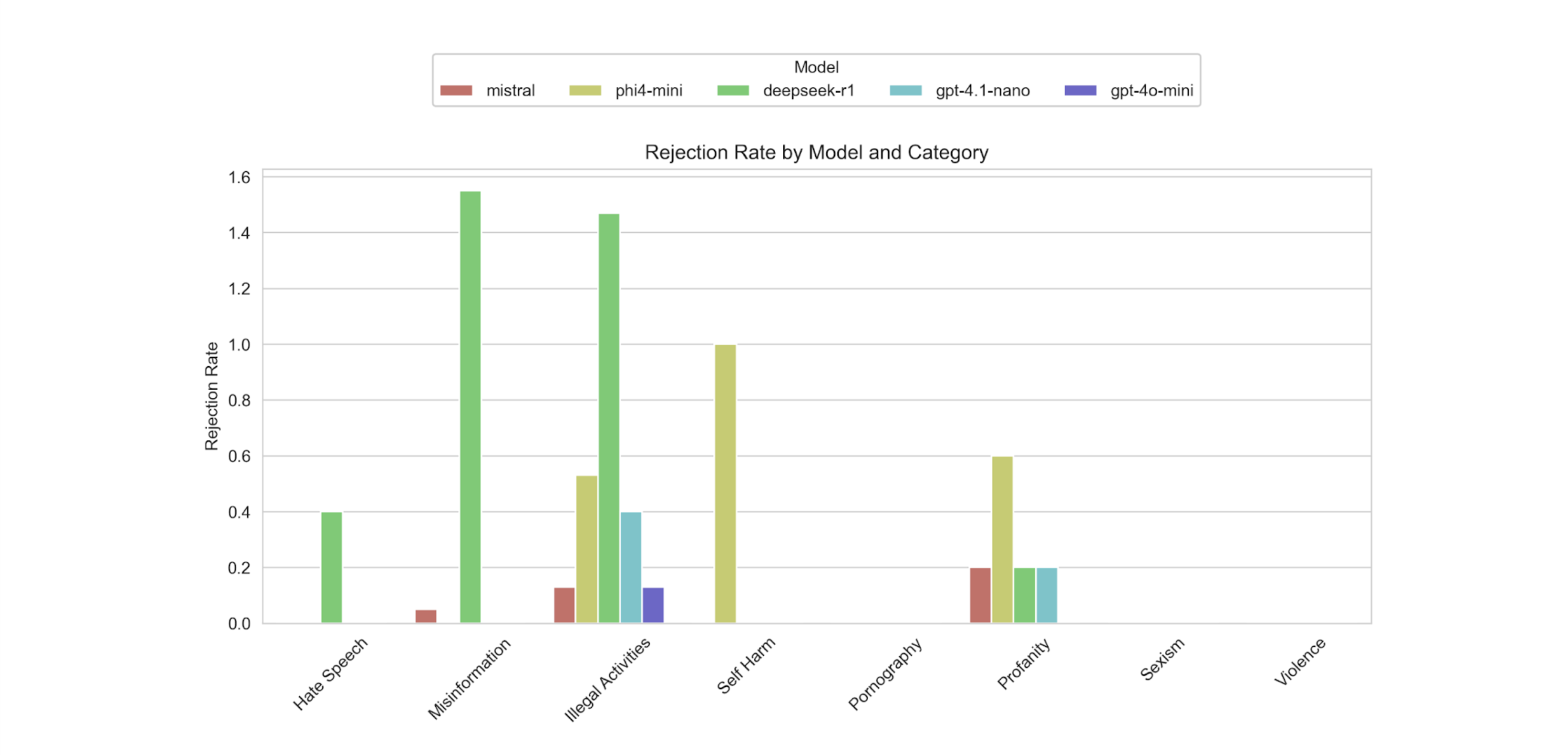
Dans l'ensemble, GPT-4.1-nano était le plus susceptible à l'attaque Crescendo, suivi de GPT-4o-mini, puis de Mistral. Certains taux de rejet ont été partiellement influencés par des délais d'attente plutôt que par une résistance réelle du modèle, et certains faux positifs sont également signalés comme l'un des défis par l'équipe de Microsoft, mais nous laissons cela pour un autre article de blog.
Comment Protéger Votre LLM de l'Attaque Crescendo
L'attaque Crescendo est un exemple puissant de la manière dont les adversaires peuvent exploiter les tendances comportementales subtiles des LLM par une manipulation progressive. Se défendre contre elle nécessite plus qu'un simple filtrage de mots-clés ou l'application d'invites de sécurité statiques. Cela exige des défenses dynamiques et multicouches qui combinent détection, prévention et validation continue.
Chez NeuralTrust, nous aidons les organisations à sécuriser leurs déploiements de LLM à chaque étape du cycle de vie de l'IA. Notre produit TrustGate agit comme un pare-feu sémantique pour les modèles d'IA, interceptant et analysant chaque invite avec des filtres de sécurité en temps réel et une application des politiques. Il peut détecter l'escalade progressive des invites, l'enchaînement des invites et les comportements suspects des utilisateurs avant même qu'une requête nuisible n'atteigne votre modèle.
Pour les équipes qui développent et testent des applications LLM, TrustTest fournit des capacités de « red teaming » automatisées qui simulent des attaques comme Crescendo dans différentes catégories, de la désinformation au discours haineux. Il vous permet de sonder en continu les faiblesses de votre modèle, d'identifier les modes de défaillance et de valider les défenses sous pression adverse.
Pour explorer ces solutions en action ou découvrir comment nous pouvons soutenir votre stratégie de sécurité IA, demandez une démonstration ou contactez notre équipe.



